Although most of my programming these days is in Haskell, I previously spent years using interpreted languages such as Ruby, Python, and PHP. Two out of three of these are languages I would still use happily, and indeed I still find myself occasionally reaching for Ruby even for just running maintenance operations such as migrating PostgreSQL databases. Since I package things separately, there’s no reason not to use an approach like this within a project, even when the majority of the code is written in a different programming language. Having used a variety of continuous integration environments over the years, such as Jenkins and Travis CI, I’ve come to rely on Concourse CI for most of the pipelines automation work I do. Concourse CI hasn’t been without problems, but these days it’s usually pretty stable, and a strong choice when it comes to devops automation. In this post, I show a pattern for CI packaging pipelines, such as might be used for Ruby 2.7, or with small modifications, other languages, via the latest Concourse CI 6.4.1.
Pipeline overview
One of the nice things about Concourse CI is it automatically creates a visual overview of each pipeline. The reference I’m using here is the packaging pipeline for Tigrosa, a high-performance authentication and authorisation proxy I’m working on. It’s not currently released separately, but it’s already used within Isoxya, the next-generation crawling system I’ve developed, which is able to programmatically crawl the internet and process data using plugins written in pretty much any modern mainstream programming language. The component we’re interested in here is db-mig, a database migration program which uses Ruby.
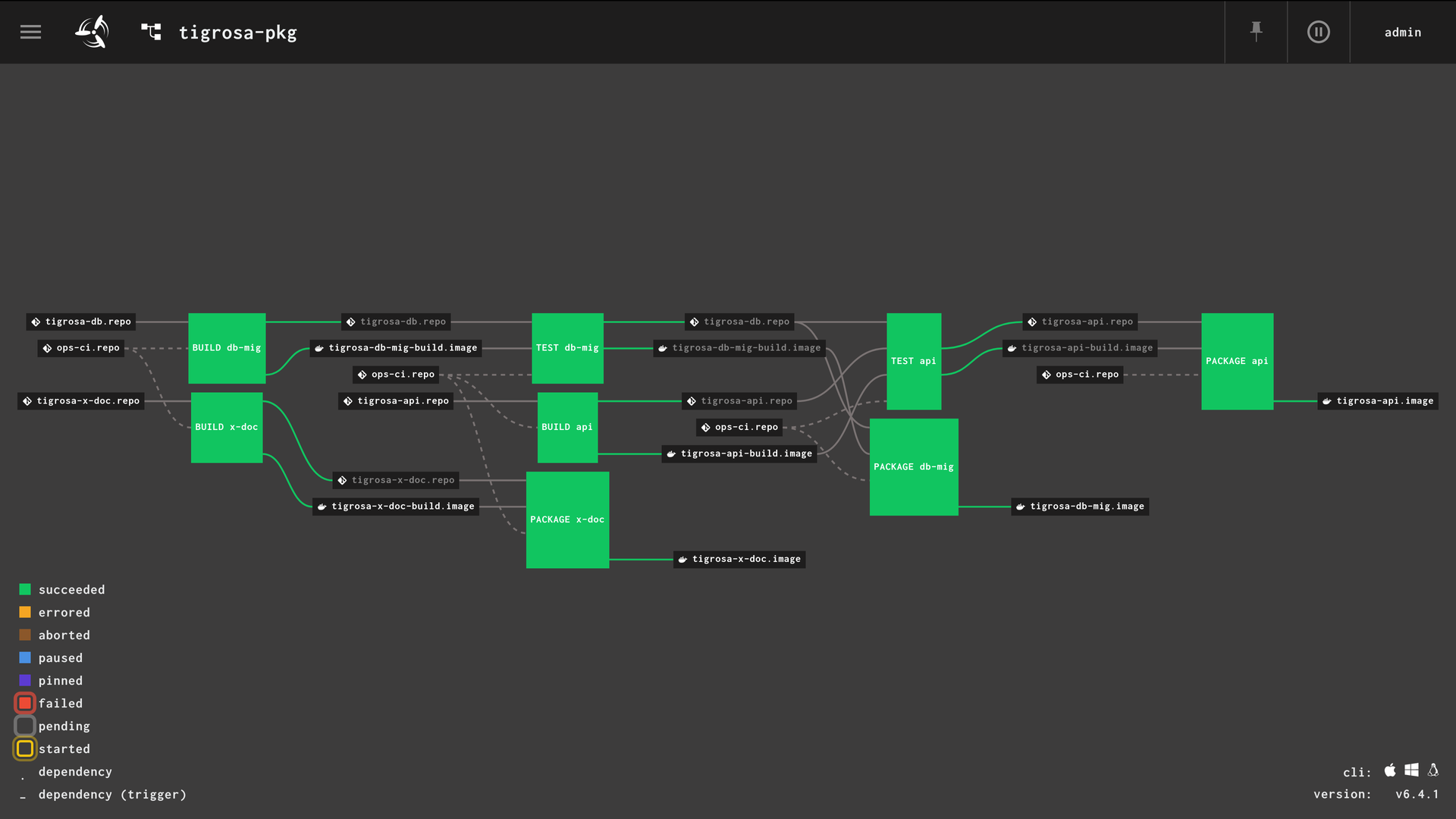
Pipeline resources
Concourse CI writes definitions in YAML, which is able to be checked into a VCS such as Git. I highly recommend doing this regardless of which CI system you’re using, as it enables you to easily preview, deploy, and revert build system changes. Wherever possible, I call external scripts rather than embed code directly in the pipeline configuration. I used to store this in the program repository, but so much of it was the same, I recently unified the approach to use a centralised ops-ci repository, which is loaded as a pipeline dependency. This enables related Shell scripts to be checked in and deployed, just like regular programs.
Git repositories
We specify the Concourse CI and Shell ops-ci and Ruby tigrosa-db repositories as resources used in the pipeline, linked to secrets, using the Git resource. These secrets are able to use a credential management system, or be embedded directly depending on the security model.
#===============================================================================
resources:
#-----------------------------------------------------------------------------
# REPO
-
name: ops-ci.repo
type: git
icon: git
source:
uri: git@example.com:ops-ci.git
branch: master
private_key: ((ssh.key.private))
-
name: tigrosa-db.repo
type: git
icon: git
source:
uri: git@example.com:tigrosa-db.git
branch: master
private_key: ((ssh.key.private))
Container images
We specify the build and package container images, using the Registry Image resource. Until recently, I’d been using the older Docker Image resource, but the Registry Image resource is more modern.
#-----------------------------------------------------------------------------
# IMAGE
-
name: tigrosa-db-mig.image
type: registry-image
icon: docker
source:
repository: registry.example.com/tigrosa-db-mig
username: ((registries.example.username))
password: ((registries.example.password))
-
name: tigrosa-db-mig-build.image
type: registry-image
icon: docker
source:
repository: registry.example.com/tigrosa-db-mig-build
username: ((registries.example.username))
password: ((registries.example.password))
Pipeline jobs
Within each pipeline, there are jobs, which define what actions should be performed. For a packaging pipeline, I usually run three jobs per program:
-
Build: build the source code into a build container image, such as is detailed in Building Haskell 8.8.3 programs using Dockerfiles
-
Test: run any tests, whether explicit tests such as unit tests, or smoketests such as ensuring the program can actually be compiled; for a database migration program, I migrate the database here, rather than in other programs (such as an API or web application), and define relationships to trigger tests from other programs in the pipeline every time the database schema is updated
-
Package: package the program using the build container image into a deployable artefact, such as a package container image, or for a compiled language, potentially a package manager repository or other way of distributing the binaries
Build job
I used serial_groups to restrict the number of builds which can happen simultaneously in the pipeline; this helps to prevent a triggered storm when a parent dependency is updated, preventing overload of the CI workers. ops-ci.repo and tigrosa-db.repo are used as inputs, with trigger used to trigger the job only when the program source has changed. This means that although the latest CI shared code will always be used, updating a CI packaging script, for example, won’t result in everything being rebuilt. For the few times I want to make an exception, I simply trigger the job manually. ops-ci.repo/ci/meta.yml is a script I use to generate metadata about the build; this typically uses git describe or similar to generate a deterministic version for the artefacts, which are easy to trace and update.
#===============================================================================
jobs:
#-----------------------------------------------------------------------------
# BUILD
-
name: BUILD db-mig
serial_groups:
- build
plan:
-
get: ops-ci.repo
-
get: tigrosa-db.repo
trigger: true
-
task: META
file: ops-ci.repo/ci/meta.yml
input_mapping:
i-ops-ci: ops-ci.repo
i-repo: tigrosa-db.repo
output_mapping:
o-meta: meta.tmp
The next task within the job is the main build task. This uses ops-ci.repo/ci/build.yml to build the intermediary container image using the program’s Dockerfile, such as may be used for development and running tests. Since this image is used throughout the pipeline from this point onwards, there is no need to reinstall dependencies such as Ruby gems, and the installed packages are in fact bit-frozen and copied even to the deployable package container image. This provides a high degree of certainty within the CI pipeline, and makes it possible to debug issues simply by downloading the running the relevant container image locally (or using Fly to intercept the stage and enter that container directly within the pipeline). The build definition specifies to use repository: vito/oci-build-task, which uses the new OCI Build Task, which replaces the older Docker Image resource approach. Currently, it is necessary to run this task with privileged similar to the Docker Image resource; however, work is being done to remove this requirement.
-
task: BUILD
file: ops-ci.repo/ci/build.yml
input_mapping:
i-ops-ci: ops-ci.repo
i-pkg: tigrosa-db.repo
output_mapping:
image: image.tmp
privileged: true
Finally, I upload the image to the container registry, along with the tags generated as part of the metadata.
-
put: tigrosa-db-mig-build.image
params:
image: image.tmp/image.tar
additional_tags: meta.tmp/tags
Test job
For the test job, we again use the ops-ci.repo shared code, as well as the tigrosa-db.repo. Now, however, we use the tigrosa-db-mig-build.image intermediary container image, and not only trigger this job from those resources, but also use passed to lock the job to the build job. This ensures that the test job will only run if the build job passes, and for the same versions of dependencies.
#-----------------------------------------------------------------------------
# TEST
-
name: TEST db-mig
plan:
-
get: ops-ci.repo
-
get: tigrosa-db.repo
passed: [BUILD db-mig]
trigger: true
-
get: tigrosa-db-mig-build.image
passed: [BUILD db-mig]
trigger: true
Finally, we execute the actual testing or migrating task. For a database migration program, ops-ci.repo/ci/test-ruby-migrate.yml runs bundle exec rake db:migrate. For a different program such as an API or web application, this executes any unit tests, connected to the CI database migrated here.
-
task: TEST
image: tigrosa-db-mig-build.image
file: ops-ci.repo/ci/test-ruby-migrate.yml
input_mapping:
i-ops-ci: ops-ci.repo
i-repo: tigrosa-db.repo
params:
DATABASE_URL: ((svc.db.tgr))
Package job
The final stage of the packaging pipeline is the package job. This is similar to the build job, but uses those inputs to create the deployable artefacts. For a compiled language such as Haskell or Clojure, these artefacts are the binaries or JARs. For an interpreted language such as Ruby, however, typically the same dependencies are required as for the build job. Rather than reinstall third-party dependencies such as Ruby gems, however, we bit-freeze the dependencies by copying the installation directories directly. This is the same in principal to copying the node_modules directory in Node.js. Similar to the previous jobs, we restrict parallel execution by using serial_groups, use ops-ci.repo, tigrosa-db.repo, and tigrosa-db-mig-build.image as inputs, and call ops-ci.repo/ci/meta.yml to generate metadata. Concourse CI pipelines cannot share data between jobs, so it’s necessary to either store and retrieve this metadata, or to regenerate it. Since I’ve made it deterministic and it incurs minimal computational expense, I simply run it again.
#-----------------------------------------------------------------------------
# PACKAGE
-
name: PACKAGE db-mig
serial_groups:
- package
plan:
-
get: ops-ci.repo
-
get: tigrosa-db.repo
passed: [TEST db-mig]
trigger: true
-
get: tigrosa-db-mig-build.image
passed: [TEST db-mig]
trigger: true
-
task: META
file: ops-ci.repo/ci/meta.yml
input_mapping:
i-ops-ci: ops-ci.repo
i-repo: tigrosa-db.repo
output_mapping:
o-meta: meta.tmp
Next we use the intermediary build container image and the inputs to package the data. ops-ci.repo/ci/package-ruby-migrate.yml copies the package Dockerfile, Gemfile and Gemfile.lock, and also BUNDLE_PATH, to a directory from which it can be extracted within the build task. This uses Concourse CI to create a mount, accessible within both the package and build tasks, whilst switching the container being run mid-way.
-
task: PACKAGE
image: tigrosa-db-mig-build.image
file: ops-ci.repo/ci/package-ruby-migrate.yml
input_mapping:
i-ops-ci: ops-ci.repo
i-repo: tigrosa-db.repo
output_mapping:
o-pkg: pkg.tmp
Similar to the build job, ops-ci.repo/ci/build.yml builds a container image. This time, however, we use the deployable pkg/Dockerfile, rather than the intermediary development Dockerfile. Again, this needs to be privileged, at least for now.
-
task: BUILD
file: ops-ci.repo/ci/build.yml
input_mapping:
i-ops-ci: ops-ci.repo
i-pkg: pkg.tmp
output_mapping:
image: image.tmp
privileged: true
Finally, we upload the deployable container image to the image repository. This is then able to be used elsewhere, either within a deployment pipeline (my approach for a few years), or directly by hosts within a container orchestrator using a pull-based approach. There are advantages and disadvantages to either method, and which I would recommend would likely depend on the project, infrastructure, and team.
-
put: tigrosa-db-mig.image
params:
image: image.tmp/image.tar
additional_tags: meta.tmp/tags
#===============================================================================